𝄢 BASS
Benchmarking Audio LMs for Musical Structure and Semantic Reasoning
* Equal contribution.
University of Washington, Ohio State University, Allen Institute for AI
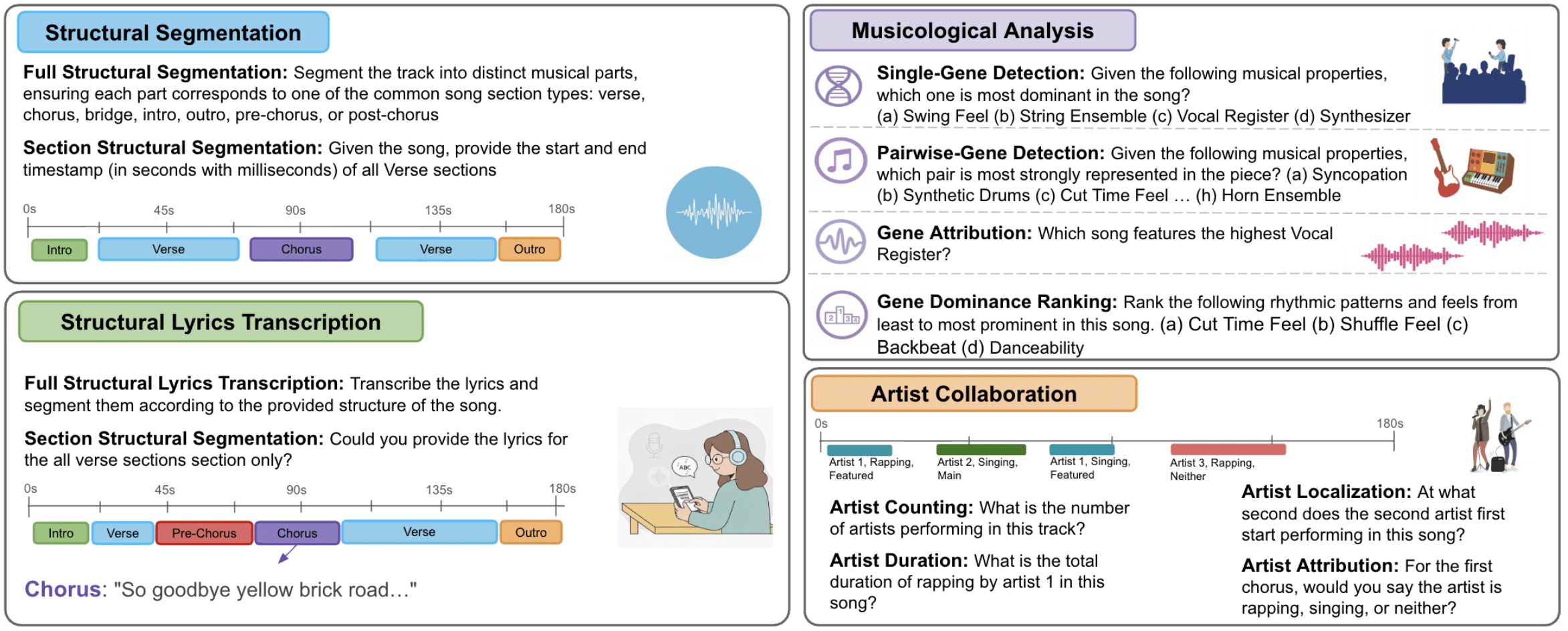
Overview of the tasks included in BASS, designed to evaluate audio LMs on musical understanding requiring long-term structure or hierarchical reasoning. It contains twelve tasks across four categories: structural segmentation, structural lyrics transcription, musicological analysis, and artist collaboration.
Abstract
Music understanding is a complex task that often requires reasoning over both structural and semantic elements of audio. We introduce BASS, designed to evaluate music understanding and reasoning in audio language models across four broad categories: structural segmentation, lyric transcription, musicological analysis, and artist collaboration. BASS comprises 2658 questions spanning 12 tasks, 1993 unique songs and covering over 138 hours of music from a wide range of genres and tracks, crafted to assess musicological knowledge and reasoning in real-world scenarios. We evaluate 14 open-source and frontier multimodal LMs, finding that even state-of-the-art models struggle on higher-level reasoning tasks such as structural segmentation and artist collaboration, while performing best on lyric transcription. Our analysis reveals that current models leverage linguistic priors effectively but remain limited in reasoning over musical structure, vocal, and musicological attributes. BASS provides an evaluation framework with widespread applications in music recommendation and search and has the potential to guide the development of audio LMs.
Metrics
The metrics displayed in the leaderboard and table are normalized to be between 0-100%. For the Artist Collaboration and Musicological Analysis tasks, the exact match accuracies (EMA) are random chance normalized, so that the scores shows the improvement over random chance. For the Structural Lyrics Transcription tasks, the Inverted Word Error Rate (IWER) is used, which bounds the WER from 0-100%, and a higher score indicates better performance. The metric for Structural Segmentation, Intersection over Union (IoU), is already between 0-100%, so no further normalization is applied.
Model Performance — Leaderboard
Sorted by overall average (desc)
Medals: 🥇 🥈 🥉 for top 3.
| # | Model | Size | Average (%) |
|---|
Full Results Table
| # | Model | Speech | Sound | Music | Spatial | Multi-audio | Voice-chat | Instruction | Average |
|---|
Data Statistics
Question Distribution
Distribution of 2,658 questions across task categories and individual tasks
Audio Statistics
| Category | Task | # Songs | Avg. | Min. | Max. |
|---|---|---|---|---|---|
| Structural Lyrics Transcription | Full Structural Lyrics Transcription | 665 | 3.73 | 1.60 | 11.72 |
| Section Structural Lyrics Transcription | 170 | 3.97 | 2.17 | 8.44 | |
| Overall | 884 | 3.78 | 1.60 | 11.72 | |
| Structural Segmentation | Full Structural Segmentation | 74 | 3.06 | 1.70 | 10.78 |
| Section Structural Segmentation | 224 | 3.47 | 1.93 | 9.31 | |
| Overall | 298 | 3.37 | 1.70 | 10.78 | |
| Artist Collaboration | Artist Counting | 229 | 3.92 | 2.37 | 6.97 |
| Arist Duration | 327 | 3.83 | 1.34 | 6.97 | |
| Artist Localization | 247 | 3.83 | 2.37 | 6.13 | |
| Artist Attribution | 64 | 3.88 | 1.34 | 6.97 | |
| Overall | 327 | 3.83 | 1.34 | 6.97 | |
| Musicological Analysis | Single-Gene Detection | 335 | 3.15 | 1.86 | 9.23 |
| Pairwise-Gene Detection | 147 | 3.77 | 0.82 | 6.37 | |
| Gene Dominance Ranking | 33 | 3.60 | 2.58 | 4.95 | |
| Gene Attribution | 94 | 14.14 | 9.77 | 19.44 | |
| Overall | 484 | 5.57 | 0.82 | 19.44 |
Analysis
The BASS benchmark reveals significant insights into current audio understanding capabilities. Models show varying strengths across different audio domains, with speech processing generally achieving higher accuracy than music and spatial audio understanding.
Multi-audio reasoning and long-form content processing remain challenging areas, highlighting opportunities for future model development. The benchmark also demonstrates that instruction-following capabilities in the audio domain lag behind those in visual and textual modalities.
Section Level Performance
For tasks requiring section-level understanding, models tend to perform better when required to segment the full song, instead of specific sections. This suggests that models may be leveraging early sections as context to inform their predictions on later sections.
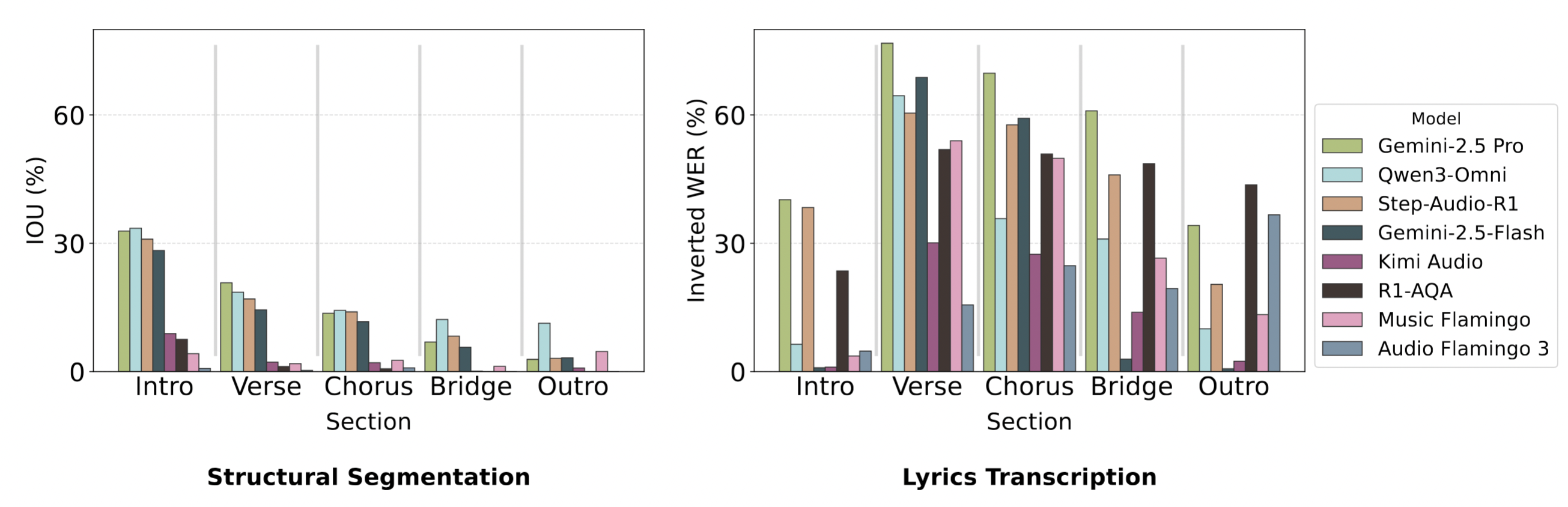
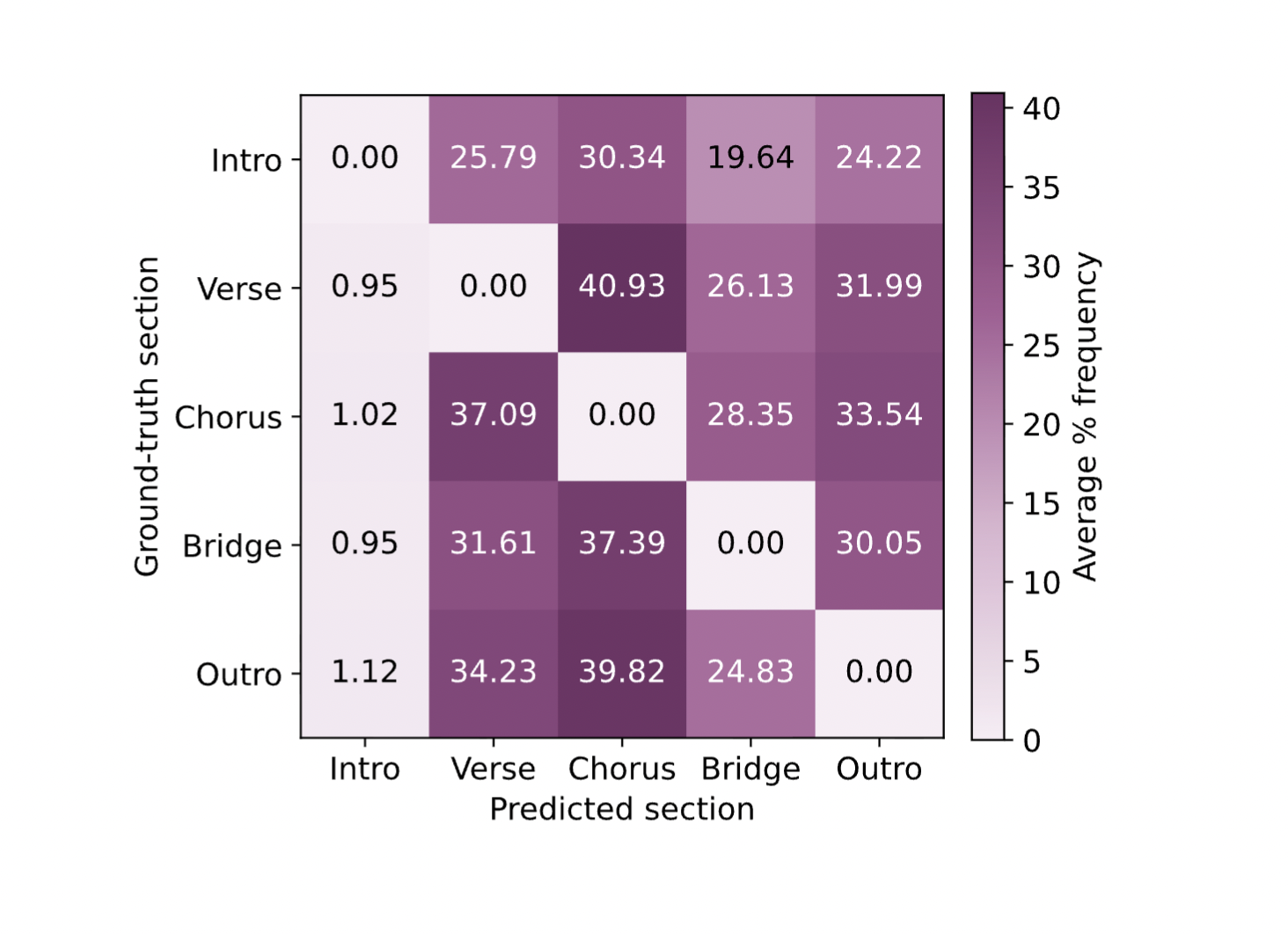
For structural segmentation, models perform better on sections typically appearing earlier in songs, such as the intro. However, in the structural lyrics transcription tasks, models perform worse on the intro sections, likely due to overtranscribing the shorter intro sections. This is evident in the confusion matrix, where the verse is often misclassified as the intro.
Vocal Delivery Style
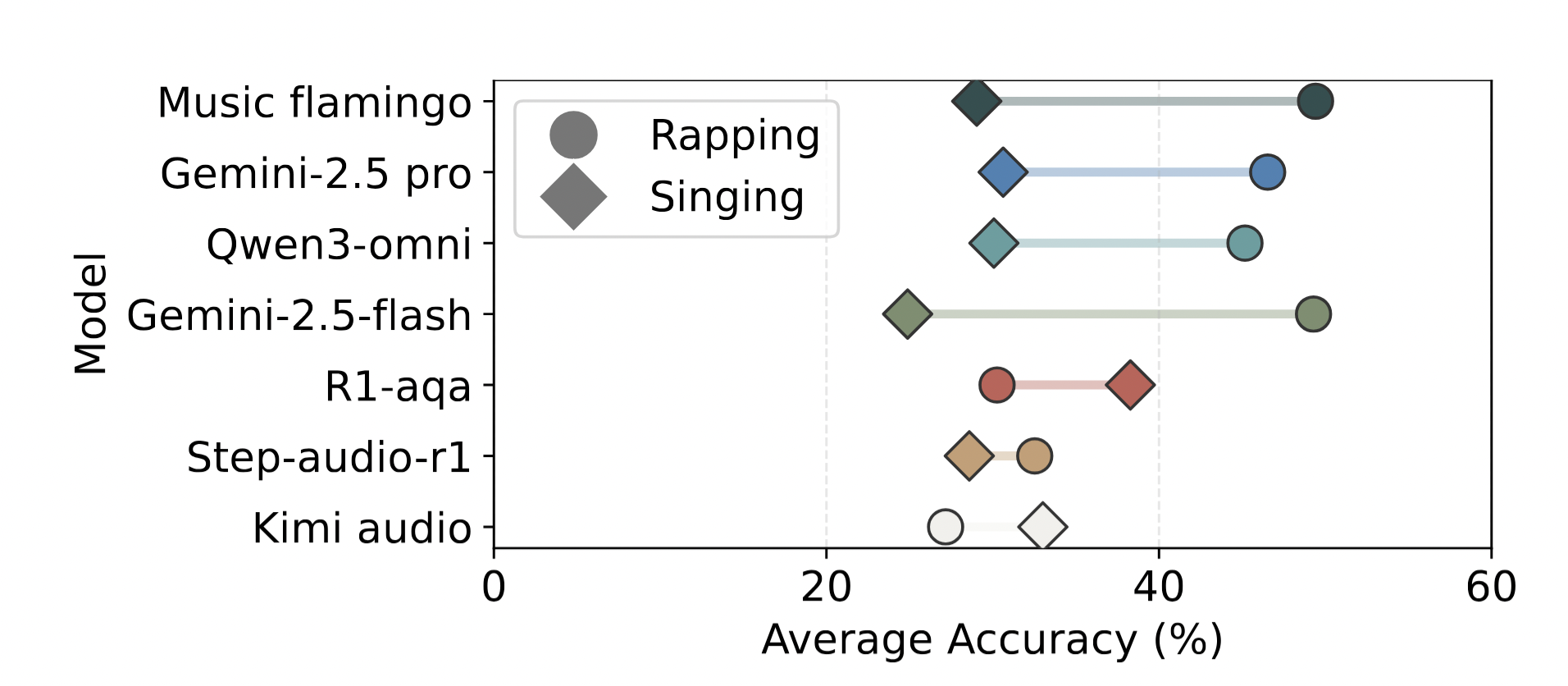
Across most models, performance tends to increase when asked about rapping rather than singing. This might be due to rapping more closely resembling spoken language, which models are typically trained on
Whisper Transcript + Audio LMs
We experimented with cascaded models, feeding in Whisper transcripts as well as the audio for the structural lyrics transcription tasks.
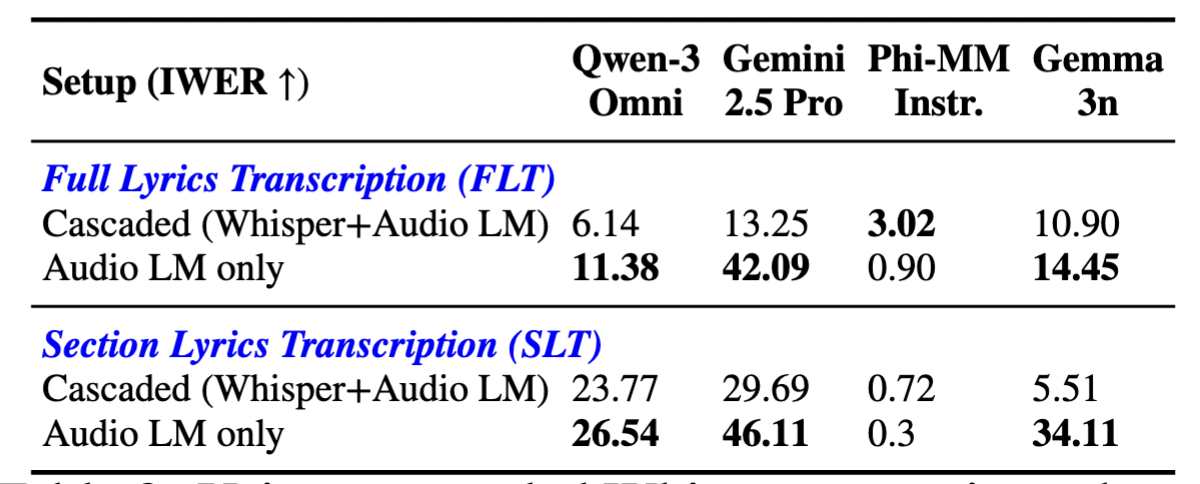
Models tend to perform worse when provided with the Whisper transcripts in addition to the audio input. The errors in the Whisper transcripts may be propagating through to the final predictions, where the same issues in section confusion only make performace worse.
Source Separated Audio
Using BS-RoFormer model, we created source separated audio inputs that only contain the vocals for the structural segmentation and structural lyrics transcription tasks.
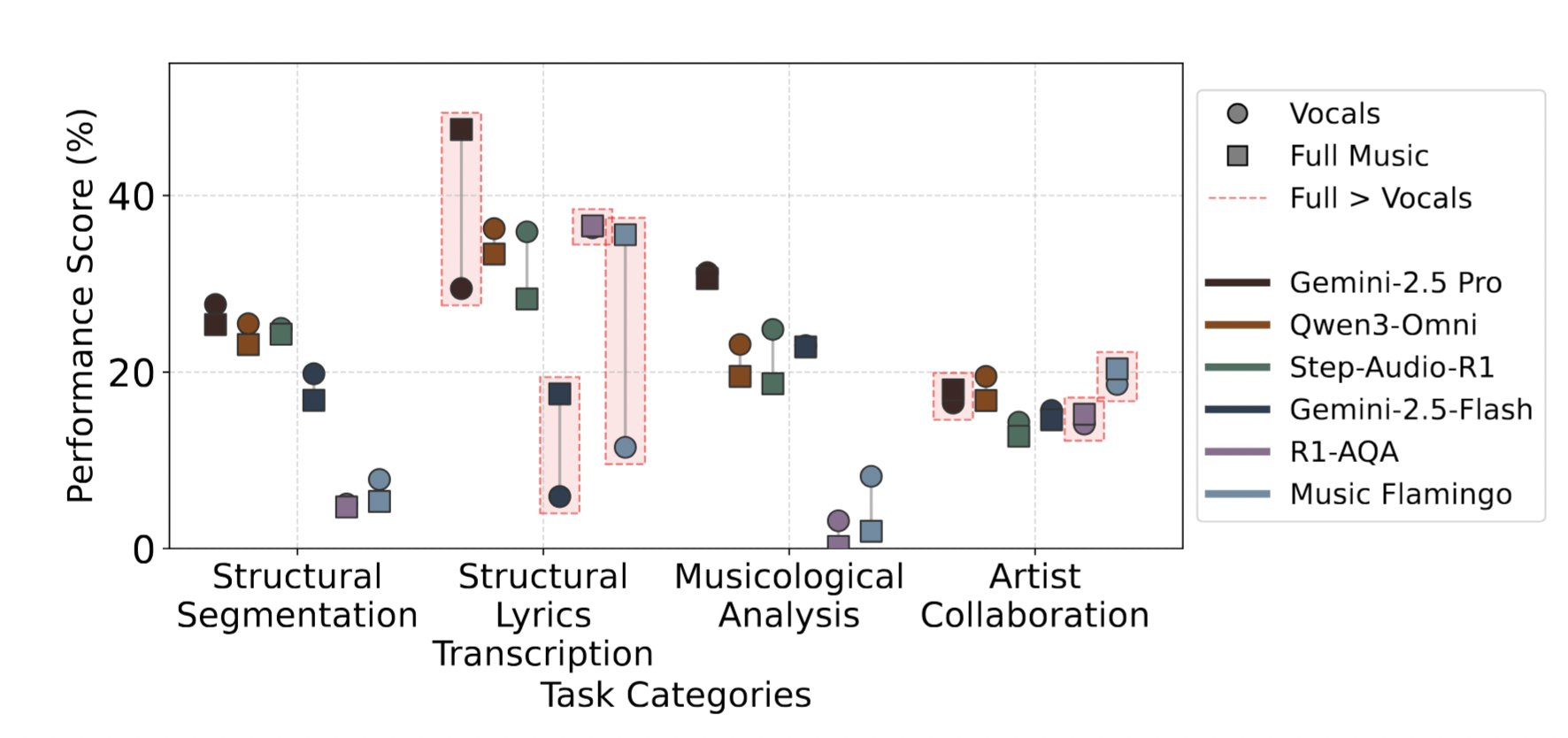
All tasks that showed a degradation in performance using source separated input is highlighted in red. Most significantly, the structural lyrics transcription tasks suffer from only vocal input, likely due to the presense of instruments being important context for section boundaries. Across the rest of the tasks, there is no significant performance increase from using vocals only audio.
Does Reasoning Help?
To analyze if reasoning help models understand music, we compare the performance of Qwen3-Omni, a hybrid model that can be inferenced with thinking turned on or off.
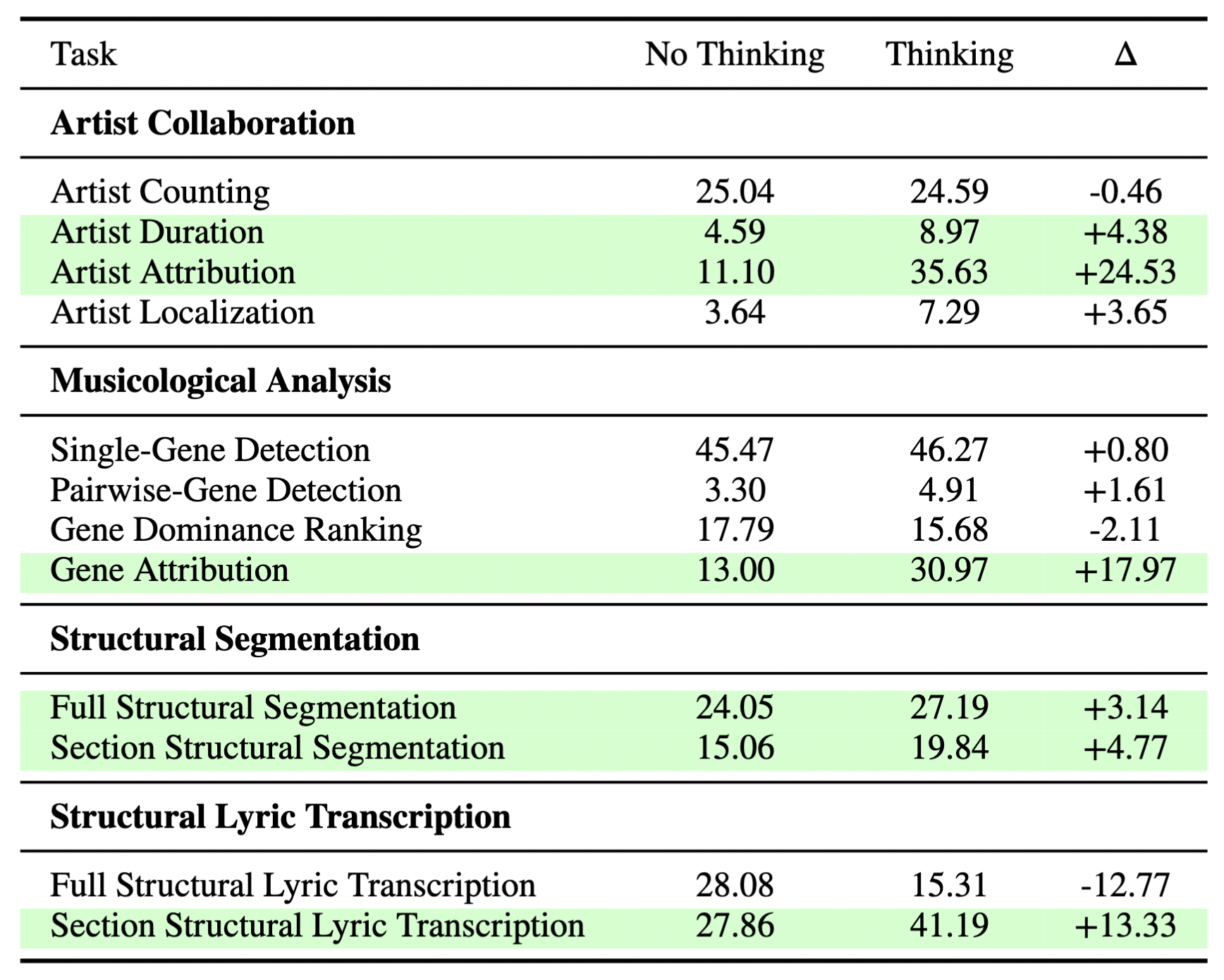
Tasks where reasoning significantly helps performance are highlighted in green. The table shows indicate that enabling “thinking” significantly improved model performance on 6 out of 12 tasks in BASS. We observed the largest performance gains on Artist Attribution (+24.53), Gene Attribution (+17.97), and Section Lyrics Transcription (+13.33), all of which are statistically significant (𝑝 < 0.001) after Holm-Bonferroni correction. Although tasks like Full Lyrical Transcription and (-12.77) and Gene Dominance Ranking (-2.11) show small negative performance deltas where “thinking” degrades performance, we did not find any cases of statistically significant degradation.
Are LMs Reasoning or Memorizing Music
To investigate whether audio LMs are reasoning about music or simply retreiving memorized information from their training data, we analyze models that can take in text only input, namely Gemini 2.5 Pro, Gemini 2.5 Flash, and Qwen3-Omni. Instead of providing the audio input, we provide only the name of the song and the artist as input to the model.